Update
Version 1.0.4.6 is available on chrome web store. Its compatible server sample application is published on GitHub. , THIS DOES NOT MEAN ENDORSEMENT by nor AFFILIATION with JetBrains, but JetBrains granted a subscription for Live Caption Analytics. Please find details here.
Features
Major features are captured in another page (here).
Purpose
Live caption analytics is a part of the project called "own voice" where "own voice" democratizes learning opportunities and protects the learner's ownership of voice interaction texts. It promotes a fair share of online word-by-word activity records that ought to belong to each learner, whose data are usually solely held by service providers.
In addition to the primal cause of protecting the ownership, live caption analytics can provides beneficial, live feedback that are calculated real-time for a user of a browser. Texts in feedback can include recommendation based on interactions from immediate records (5-10 second) to long-term archive (1-2 year) among multiple participants of discussion(s) across a series of sessions.
System
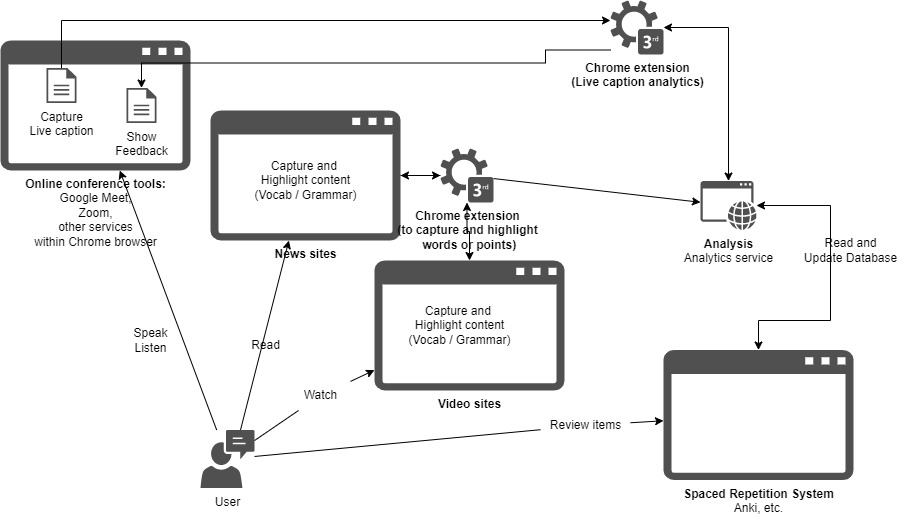
Live caption analytics is a Chrome extension (available here) to help language learners optimize their learning through feedback and acknowledgement by sending live captions to your designated servers to perform analytics and to store transcripts in a separate spreadsheet. The server, then, can return the calculated results back to this extesion which renders the response to the screen. The extension itself, in fact, offers only the simple, but critical features that send captions and and receive response from your server. The image below shows the interactions among components. Component 1) Chrome extension reads captions on the screen and send them to 2) analysis server and 3) record server with explicit grant to send the subtitle data. Then, 2) analysis server will A) perform predefined calculation from the received captions and accumulated caption data that may be as old as the user started to use the extension and B) return the analysis result to the 1) Chrome extension that will show the result. In addition to the caption mechanisms provided by Google Meet and Zoom, the 1) Chrome extension provides captioning capabilities through browser built-in speech recognition for other services that are missing live caption functionality.
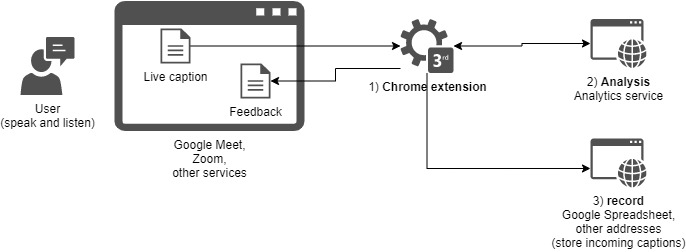
Live caption analytics (chrome extension) has three main components 1) chrome extension, 2) analysis, and 3) record. For further information of this categorization and features availble under each category, visit GitHub repo README.
Please note that without a URL of analysis server, this extension will only work for Spreadsheet that records captions as in the third component, record. An analysis server address from any service of your choice can provide a type of analysis and interactions unique to that service provider. A sample service can be installed from GitHub repo onto your server to try, adapt, and develop to elevate.
Installation
Full range of functionalities will be available after you add 1) chrome extension, set the link to 2) analysis server and follow steps to specify details of how to record captions and what feedback the application should provide. Procedure is outline here.
Sponsoring own voice
I am committed to gradual, but steady improvements of the sample code and am asking you to support the project financially. All the expenses are currently covered by the developer, me. Your help will propel further development and supporting activities, and will be pooled for the sample server to which some users are invited to try out the features and explore the service.
Proposed interactions
The intraction model of the tool will help facilitator or instructor to 1) provide immediate, on-spot feedback, 2) synthesize records across time and participants, 3) accelerate discussion through automatically retrieving resources., and 4) integrate learning resources.
1. Provide immediate, on-spot feedback
In addition to the essential benefit of owning your audio interaction captured in text, real-time interaction offers significant advantages that are missing in delayed feedback from analyzing the fixed, complete, finalized text. Merits from immediate, impersonal, non-disruptive feedback include 1) more on-spot, relevant behavioral improvement through self-correction for local errors in language learning setup as one example, largely due to its promptness, and 2) less embarassing experience and more stable, positive affective filter effects because the learner can keep their face due to the absence of confrontation by peer learners or the instructor, and 3) stable lesson or convesation flow that can be easily broken by human interruption.
2. synthesize records across time and participants
Captured information across time and groups will enable analytics to provide recommendation or helpful information relevant to the currently running interaction by 2-a) collectively reviewing past records of the single, current learner and by 2-b) reading captions for discussion groups which are concurrently happening in the same room or for the same lesson. The figure below illustrates the overview of 2-b interaction in which live transcripts from different groups will feed analytics service and the service will summarize the relevant information such as topics or positions of the on-going conversation.
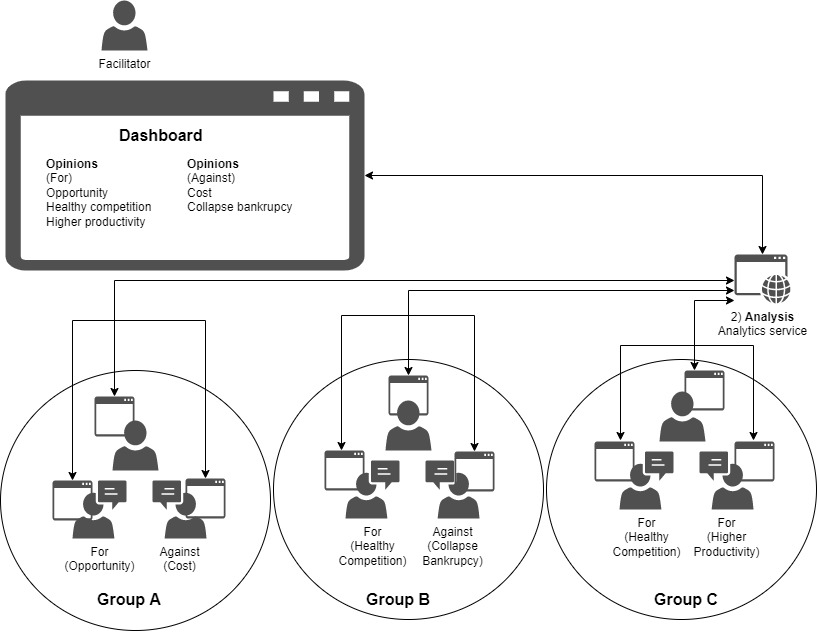
3. accelerate discussion through automatically retrieving resources.
As the machine can listen to all the utterances of the whole participants, it can also retrieve relevant information for the further discussion for the specific group and can present the list of summaries that may trigger deeper or wider discussion.
4. integrate learning resources.
The benefits of the mechanism should go beyond accumulating interactions, and should touch other types interactions or learning activities. With one of the most challenge forms of learning actions, speech record captured and extension can prompt users via screen, it is comparatively less complicated to integrate other types of learning opportunities such as reading books/documents and listening to a video clip. For example, captured captions can suggest more relevant materials to read or users can activate the knowledge by using expressions or brief information that they have just learned from other sorts of document through visible guidance on the screen from analytics shown on the screen.
The following sections 4-1 and 4-2 will show 4-1. application in PBL settings and 4-2. application to integrate learning.
4-1. application in PBL settings
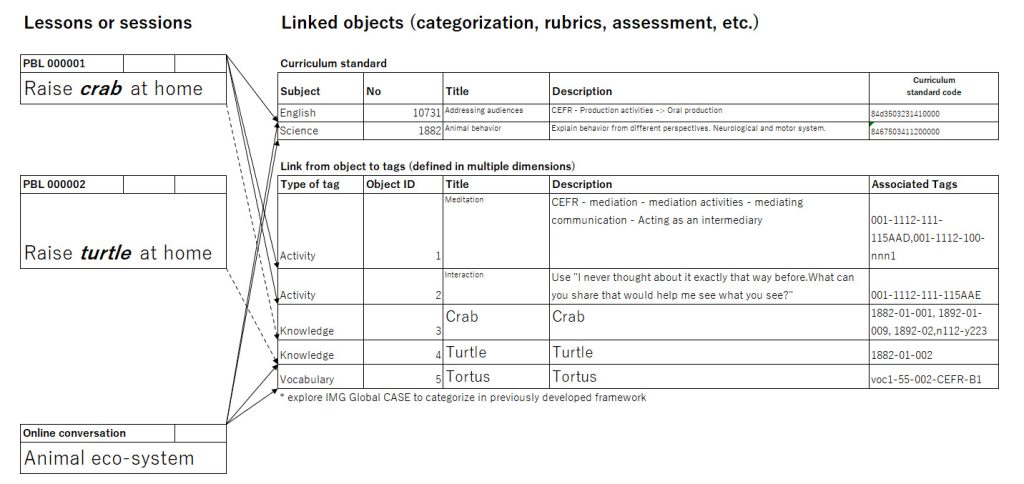
The figure below describes a sample structure to map activites to multi-dimensional objects. On the left, the box shows a modelled lesson or actual session. The right part shows a table of a fraction of curriculum standard or catalog of knowledge/skills/competency and a table of building blocks with tags. Each arrow links sessions on the left with curriculum and objects on the right.
In the example in the figure, the following activities and recommendation may promote a type of learning.
4-1-1) a user will participate in a PBL class and collaboratively find solution(s) to have a crab at their house
The activity covers some of the items in curriculum standard to use English, and also help the learner grasp the shallow knowledge about crab (object #3) and practice mediation skill (object #1)
4-1-2) the user, on another occasion, will discuss eco-system as part of online English practice.
The sytem will suggest the previous knowledge to cover and assist the learner to practice the learned skills and accumulate more details about the topic.
4-2. application to integrate learning
A user interacts with different servics. The system captures live caption for all touch points, renders feedback, and updates learning items in such as Anki (SRS). The service envisions that it will integrate all the data inflow/outflow of all the interactions.
The integrated system may capture all the data shown in a screen as text of a blog site or all the live transcriptions in online conferencing services. This will inform the analytics about what the user has been viewing and speaking, and will enable dynamically adjusting highlight or suggestion. On highlight part, the system will coordinate highlights based on the exposure to specific points such as vocabulary use and context. For example, the urgency or necessity to review a specific set of vocabulary may drop if the user reads or speaks very frequently in the last few days. Then, the system may not highlight relevant vocabulary in news articule or videos because the user has already reviewed it sufficiently. On the flip side, suggestion part may propose vocabulary to use in a speaking session and adjust the SRS records for its last visited time for a word. The following case will illustrate how it will alter proposals. If the user watch some specific context or topic such as "democracy," then, the system can propose related vocabulary in that context, such as "decentralize" or "constituency," for speaking sessions in Google Meet or repetitive practice in Anki, an SRS.
Examples
Real-time interaction examples are illustrated below, which are available in the sample server application in the GitHub repo. Accompanied YouTube videos (here) will explain the sample stats and feedback. (An abridged Japanese version is available here) List of features are updated in "Features" sesion of the GitHub readme (here).
1. turn taking stats
2. feedback and acknowledgement
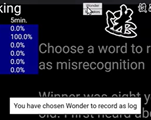
3. tracking mistakes
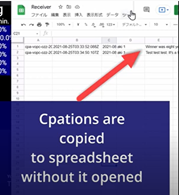
4. live update of caption to a Google Spreadsheet
The section below will explain the features.
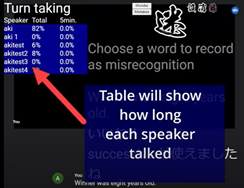
1. turn taking stats The function will show the air-time percentages of all the participants in the call. The figures will help the moderator suggest that one has to nominate one of the participants among the others.
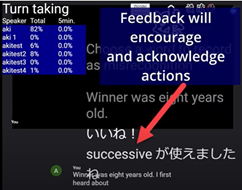
2. feedback and acknowledgement The acknowledge in this screen area praise and encourage each learner for their actions by which one remember to use newly learned vocabulary. Individual message can point to a specific use of related words that the learner is currently working on. Feedback in this kind includes 1) synonym suggestion, 2) word frequency, 3) fluency, 9) prompt, and 10) coverage from the "Features" list in GitHub readme (here).
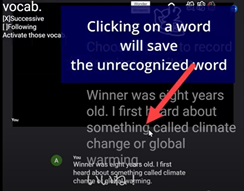
3. tracking mistakes A mere click on a word shown in the caption will store the word in the designated server as unrecognized word if this pane is used although other buttons help us remember other occasions such as where the speaker has trouble in articulating expressions or the learner likes to note a word to put into practice cycle using some kind of tools. Flexible options for the extension allow users to customize the event or the type of logs to be recorded.
4. live update of caption to a Google Spreadsheet The use case is to update a spreadsheet while the user is in session to help one capture any additional note relevant to learning. The POST-ready Spreadsheet can consume the caption data from the extension. The live caption is reflected to the sheet. A sample code is available in a public source code hosted on GitHub (here).